
79 Zettabyte of data was generated in year 2021.
Imagine if an organization has to process just 0.00001% (79 PB) of the above data!! ….. need a coffee?
Need for Data Integration
Business are often in need of actionable-insights, and that is as quickly as possible, to stay ahead in the game, or even to survive in the market. These insights help businesses take informed decisions and build data-driven or data-assisted strategies. Such as a sales strategy for up-selling and cross-selling etc.
As per following chart (Statista), our world has generated and consumed nearly 79 Zettabyte (~79,000,000,000 Terabyte) of data in just year-2021. Same chart predict a whooping 23% increase (from 79 ZB to 97 ZB) in data size for year 2022.
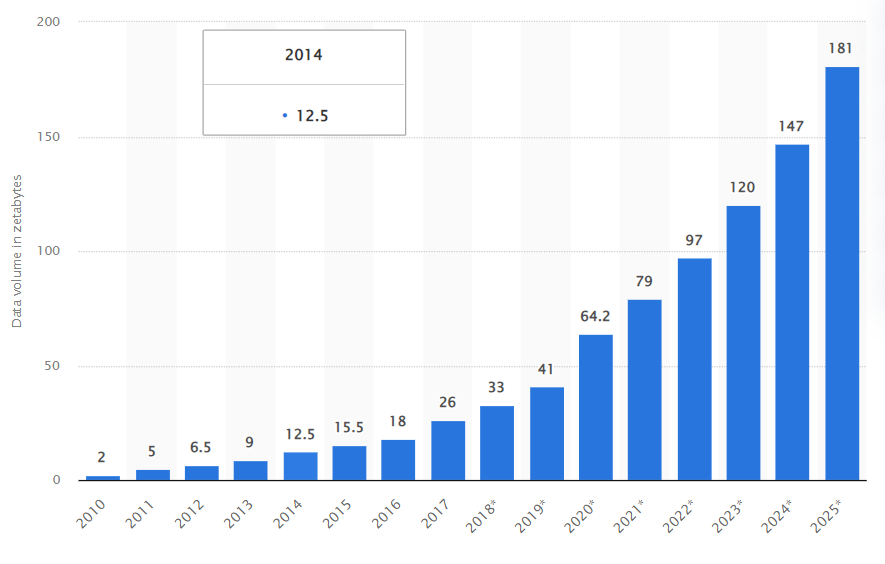
Both the data volume and sources are increasing exponentially, known as data (or information) explosion. This multi-fold explosion of data is a significant and common challenge for businesses today. It is reasonably challenging to process data from such large scale and disparate data sources, in order to get meaningful information.
Imagine if an organization had to process just 0.00001% (79 PB) of above 2021-generated data (large and complex, historical and streaming), how would it analyze and architect a cloud data solution to handle the ingestion, processing, combine, data analysis and save models for subsequent querying, reporting and visualization?
Solution: Data Integration
Insights are generated from historical and real-time data sources. Which is usually high in volume and is spread across multiple places such as relational, non-relational databases and storage systems; across cloud and on-premises.
Extracting meaning full information from disparate historical data sources and real-time data sources can only be performed if all the scattered data is unified/transformed using data integration. Once unified, data analytics provide desirable insights in order to predict or prescribe decisions.
Data integration is the process of:
- Integrating (or stitching) disparate sources of data (different type, structure and volume), by ingesting into a common place. then
- Processing (or even transforming) the data in order to
- Build a more extensive, comprehensive, standardized and unified data set
- Above dataset then is used by different business teams for exploring meaningful and actionable insights (using querying, reporting and visualizations).
Azure Technologies for Data Integration & Analytics
Microsoft Azure provide various solutions for large-scale data integration. Such as:
| Azure Technology Name | Data Integration | Data Analytics |
|---|---|---|
| Azure Data Factory (ADF) | Yes | |
| Azure Data Lake Storage | Yes with support of ADF | |
| Azure Databricks | Yes | Yes |
| Azure Synapse Analytics | Yes | Yes |
| Azure Stream Analytics | Yes | |
1. Azure Data Factory (ADF) – Data Integration
Azure Data Factory provide the ETL (Extract-Transform-Load) capability in cloud. it provides a common management interface for all of your data integration needs.
It can create workflows (known as pipelines) which can ingest data from disparate data stores on a scheduled/orchestrated manner and then transform it on scale.
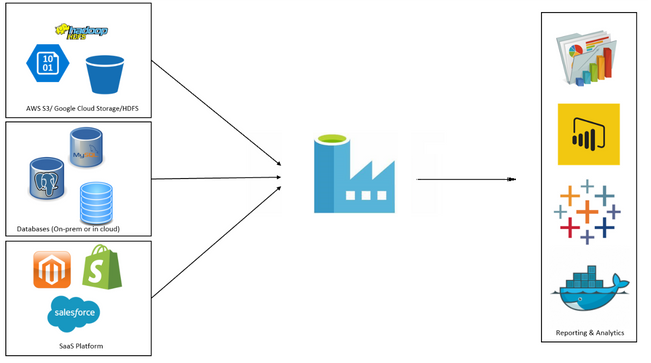
ADF supports Big data scenarios as well as relational data warehousing that uses SQL Server Integration Services (SSIS).
The following graphic shows ADF orchestrating the ingestion of data from different data sources. Data is ingested into Storage Blob and stored in Azure Synapse Analytics. Analysis and Visualization components are also connected to ADF.

Features
- ADF is fully managed, serverless and scalable solution.
- ADF allows to setup and monitor pipelines graphically
- ADF supports 90+ connectors to integrate with disparate data sources from both cloud and on-premises.
2. Azure Data Lake Storage (ADLS) – Data Integration
In general, a data lake is a repository of data that is stored in its natural format, usually as blobs or files.
Azure Data Lake Storage provides a high-performing, highly-available, secured and durable repository (storage) where you can upload and store huge amounts of structured, unstructured or semi-structured data. It helps you to quickly identify insights into your data using high-performance big data analytics capability.

Azure Data Lake supports ingesting numerous types of data such as:
- Ad-hoc data (JSON files, CSV, log files or Text data): Can be ingested using tools like AzCopy, CLI, PowerShell or Storage Explorer etc.
- Relational data (i.e. SQL DB, SQL MI, Cosmos DB etc.): Can be ingested using Azure Data Factory.
- Streaming data (i.e. events, social media, IoT etc.): Can be ingested using tools like Apache Storm on Azure HDInsight, Azure IoT Hub, Azure Events Hub, Azure Stream Analytics or Data Explorer etc.
Following diagram illustrate the overall ingestion flow and possibilities for Azure Data Lake Storage:

Features
- Performance: ADLS supports high throughput for analytics and data movement.
- Data Access: ADLS supports Hadoop and Apache HDFS (Hadoop Distributed File System) frameworks for data.
- Data Security: ADLS supports RBAC and POSIX (UNIX) based access control lists.
- Data Redundancy: ADLS leverages Azure Storage Blob Locally Redundant Storage (LRS) replication model.
- Scalability: ADLS provide highly scalable and supports numerous data types.
- Cost: ADLS storage is priced based on chosen Azure Blog Storage Levels.
3. Azure Databricks [Data Integration and Analytics]

Azure Databricks is a fully managed, cloud-based unified platform for Big Data and Machine Learning platform, which empowers developers, data science and engineering teams to accelerate AI and innovation to produce quick insightful reporting for business stakeholders.
Azure Databricks’ managed Apache Spark platform makes it simple to run large-scale Spark workloads. Data scientists can take advantage of built-in core API for core languages like SQL, Java, Python, R, and Scala
Azure Databricks offers three environments for developing data intensive applications:
| Environment | Description |
|---|---|
| Databricks SQL | Provides an easy-to-use platform for analysts who want to run SQL queries on their data lake, create multiple visualization types to explore query results from different perspectives, and build and share dashboards. |
| Databricks Data Science & Engineering | Provides an interactive workspace that enables collaboration between data engineers, data scientists, and machine learning engineers. For a big data pipeline, the data (raw or structured) is ingested into Azure through Azure Data Factory in batches, or streamed near real-time using Apache Kafka, Event Hub, or IoT Hub. This data lands in a data lake for long term persisted storage, in Azure Blob Storage or Azure Data Lake Storage. As part of your analytics workflow, use Azure Databricks to read data from multiple data sources and turn it into breakthrough insights using Spark. |
| Databricks Machine Learning | An integrated end-to-end machine learning environment incorporating managed services for experiment tracking, model training, feature development and management, and feature and model serving. |
Azure Databricks Usecases:
- Data science preparation of data
- Find relevant insights in the data
- Improve productivity across data and analytics teams
- Big data workloads
- Machine learning programs
4. Azure Synapse Analytics – Data Integration and Analytics
Azure Synapse Analytics allow you to ingest data from external sources (batch and stream processing) and then transform and aggregate it into a format suitable for analytics processing. It provides access to the streams of raw data, and the cooked business information derived from this data.
The Azure Synapse Analytics is helpful where an instant decision is required to make informed split-second buy or sell decisions.
Architecture
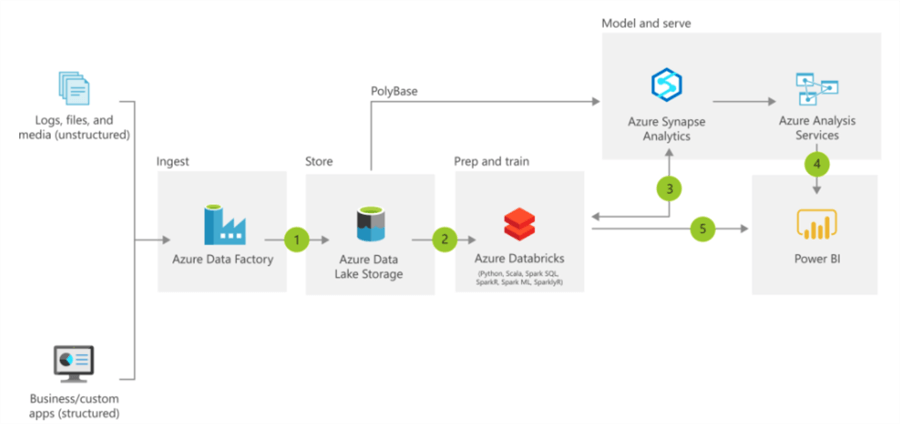
Following is the high-level architecture of Azure Synapse Analytics, in context of data integration:
Azure Synapse Analytics leverages a massively parallel processing (MPP) architecture. This architecture includes a control node (the brain) and a pool of compute nodes (computational power for even distribution of workload).

Components

Use cases:
Azure Synapse Analytics support the range of analytical types such as descriptive analytics, diagnostic analytics, predictive analytics and prescriptive analytics.
- When you have a variety of data sources use Azure Synapse Analytics for code-free ETL and data flow activities.
- When you have a need to implement Machine Learning solutions using Apache Spark, use Azure Synapse Analytics for built-in support for AzureML.
- When you have existing data stored on a data lake and need integration with the Data Lake and additional input sources, Azure Synapse Analytics provides seamless integration between the two.
- When management needs real-time analytics, you can use features like Azure Synapse Link to analyze in real-time and offer insights.
5. Azure Stream Analytics – Data Analytics
Azure Stream Analytics is a fully managed (PaaS offering), real-time analytics and complex event-processing engine.
It offers the possibility to perform real-time analytics on multiple streams of data from sources such as IoT device data, sensors, clickstreams and social media feeds.
The image shows the Stream Analytics pipeline, and how data is ingested, analyzed, and then sent for presentation or action.

Azure Stream Analytics works on the following concepts:
- Data stream– for continuous data generated by applications, IoT devices or sensors to understand change over time.
- Event processing – for continuous data stream from the events stream (CSV, JSON and Avro data format), to extract actionable insights.
Key features
- Data Ingestion from Azure Event Hubs (including Apache Kafka), Azure IoT Hub, or Azure Blob Storage.
- SQL easy filter, sort, aggregate, and join streaming data over a period.
- Extend SQL with JavaScript and C# user-defined functions (UDFs).
- Utilize Azure Stream Analytics job to:
- Route data to storage systems like Azure Blob storage, Azure SQL Database, Azure Data Lake Store, and Azure CosmosDB.
- Send data to Power BI for real-time visualization.
- Store data in Data Warehouse service like Azure Synapse Analytics
- Trigger custom downstream workflows using Azure Functions, Service Bus Topics or Queues.
Usecases
- Analyze real-time telemetry streams from IoT devices
- Web logs/clickstream analytics
- Geospatial analytics
- Remote monitoring and predictive maintenance of high value assets
- Real-time analytics on Point of Sale data
